

Recurring Network Issues in Telecom: Why They Keep Coming Back
Telecom operators with established monitoring tools still encounter Recurring Network Issues affecting the same network segments, service groups, and customer regions over time. The same customer segments call in with the same complaints, in the same regions, at roughly the same intervals.
The problem is not detection. Most operators can see their network clearly. The problem is that detection and pattern recognition are handled by separate systems — and the connection between them is manual.
1. Recurring Network Issues Persist Despite Monitoring Visibility and Limited Operational Correlation
SolarWinds identifies that interface utilization is high. Grafana shows the traffic trend. Each of these tools is accurate within its own scope.
What they do not naturally provide is cross-functional historical correlation — linking Recurring Network Issues with repeated threshold breaches, customer impact, ticket spikes, and prior incident outcomes.
Without that context, every incident appears new. Engineering teams reassemble the context manually each time. The pattern is often recognized only after it has caused significant impact — typically after the fourth or fifth recurrence on the same node.
The limitation is not visibility itself, but the operational correlation between monitoring data, customer impact, and historical incidents.
2. The Manual Coordination Problem
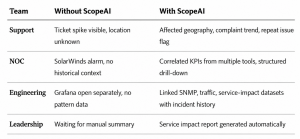
When a service degradation event occurs, the response unfolds across four separate workflows with no shared context. Support sees a ticket spike but cannot isolate where. NOC opens an incident on the core link. Engineering investigates traffic patterns separately in Grafana. Leadership waits for someone to manually compile a summary across all of the above.
According to EMA Research’s 2024 survey, unplanned downtime costs average more than $14,500 per minute for mid-sized operators. The longer teams take to coordinate during an outage, the more costly the incident becomes.
3. Technical Use Case: Customer Outage Response
A regional ISP receives complaints about degraded service. Support logs tickets. NOC identifies elevated utilization on a core link. Engineering pulls Grafana. Forty-five minutes later, the teams align — and discover this is the fourth occurrence on that same segment in two months. No team knew because the incident history lived in separate systems.
The operational distinction is not the dashboard itself, but the reduction of manual correlation work during active incidents..
4.The Role-Based Workflow
The same underlying data produces structurally different outputs depending on who is consuming it.
For NOC, it is correlated KPI movement and a path to root cause. For support, it is affected geography with historical ticket correlation. For engineering, it is cross-system datasets with incident pattern matching. For leadership, it is a service impact summary — produced without manual assembly.
Systems that expose the same raw telemetry to every role still require each team to manually translate that data into operational context. That translation work is where time is lost and where recurring patterns go unrecognized.
Conclusion
Recurring network issues are not primarily a detection problem. Operators with established monitoring tools still see the same failures return because detection and cross-team coordination are handled by separate systems with no native mechanism for connecting them.
Reducing repeat incident impact requires cross-tool correlation, pattern recognition that links current events to historical incident data, and role-specific outputs that eliminate manual assembly.
That is the gap ScopeAI is built to close.
For additional perspective on outage coordination and operational visibility in telecom environments, see our article Reducing Network Downtime in Telecom: Key Challenges and Practical Solutions.
Leave a comment